This is a Pelican plugin to calculate various statistics about a post and store them in an article.stats dictionary. You can see this in action in the sidebar on the left of this site.
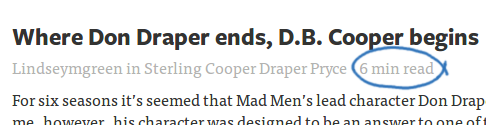
I wanted to implement the nice little “X min read” thing from Medium - and it turned out that it was easy to provide a few other interesting stats at the same time, for people to use in their templates.
The returned article.stats dictionary contains the following:
wc: how many wordsread_mins: how many minutes would it take to read this article, based on 250 wpmword_counts: frequency count of all the words in the article; can be used for tag/word cloudsfi: Flesch-kincaid Index/ Reading Easefk: Flesch-kincaid Grade Level
For example:
{
'wc': 2760,
'fi': '65.94',
'fk': '7.65',
'word_counts': Counter({u'to': 98, u'a': 90, ...}),
'read_mins': 12
}This allows you to output these values in your templates, like this, for example:
<p title="~{{ article.stats['wc'] }} words">~{{ article.stats['read_mins'] }} min read</p>
<ul>
<li>Flesch-kincaid Index/ Reading Ease: {{ article.stats['fi'] }}</li>
<li>Flesch-kincaid Grade Level: {{ article.stats['fk'] }}</li>
</ul>The word_counts variable is a python Counter dictionary and looks something like this, with each unique word and it’s frequency:
Counter({u'to': 98, u'a': 90, u'the': 83, u'of': 50, u'karma': 50, .....This can be used to create a tag/word cloud for a post.
Requirements
post_stats requires BeautifulSoup:
$ pip install beautifulsoup4Caveat Emptor
Please note that the values are a wee bit approximate - it’s surprisingly difficult to compute a perfect word count - it depends on what you count as a ‘word’, how many code samples, data tables, etc… you have in your post. Calculating the Flesch-kincaid Index/ Reading Ease/ Grade level stuff involves counting syllables - again something that is very hard to do perfectly, but quite easy to get 90% right.
In addition, the Flesch-kincaid stuff currently only works on English text, but everything else should work multi-language. I haven’t done much Unicode testing though, so patches welcome!